Fine-tune LLAVA on Autonomous Driving (ECCV 2024 Challenge)
PREVISION: PRe-training Enhanced Versatile Integration of Semantics, Images, and Object Detection for Novel Corner Case Analysis in Autonomous Driving, NTU DLCV Fall 2024 Final Project | ECCV 2024 Autonomous Driving Challenge
📍 Challenge
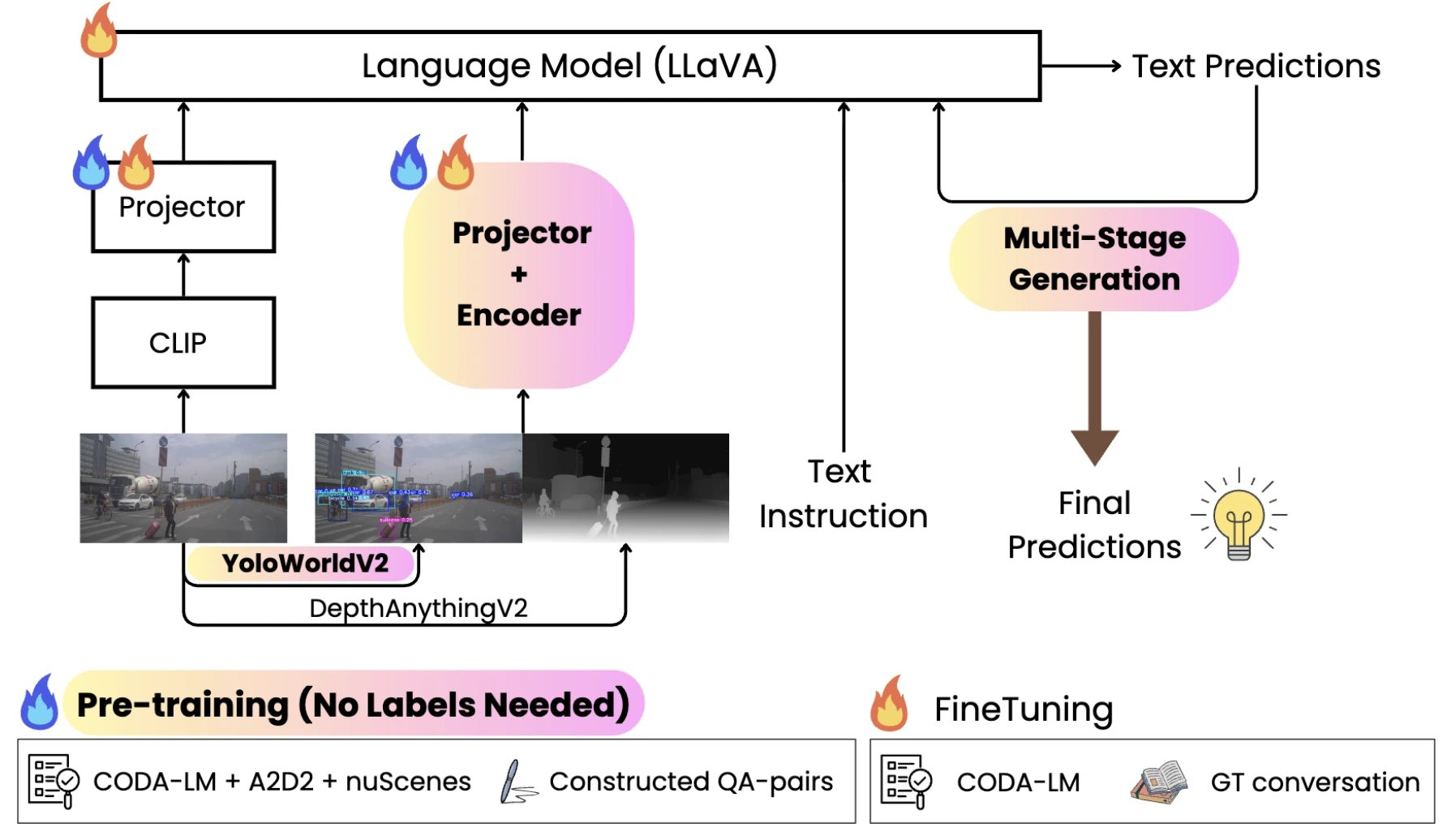
- RGB Images via CLIP vision encoder
- Object Detection (34 autonomous driving classes) via custom bounding box encoder
- Depth Information via Depth-Anything-V2
🔍 Key Findings
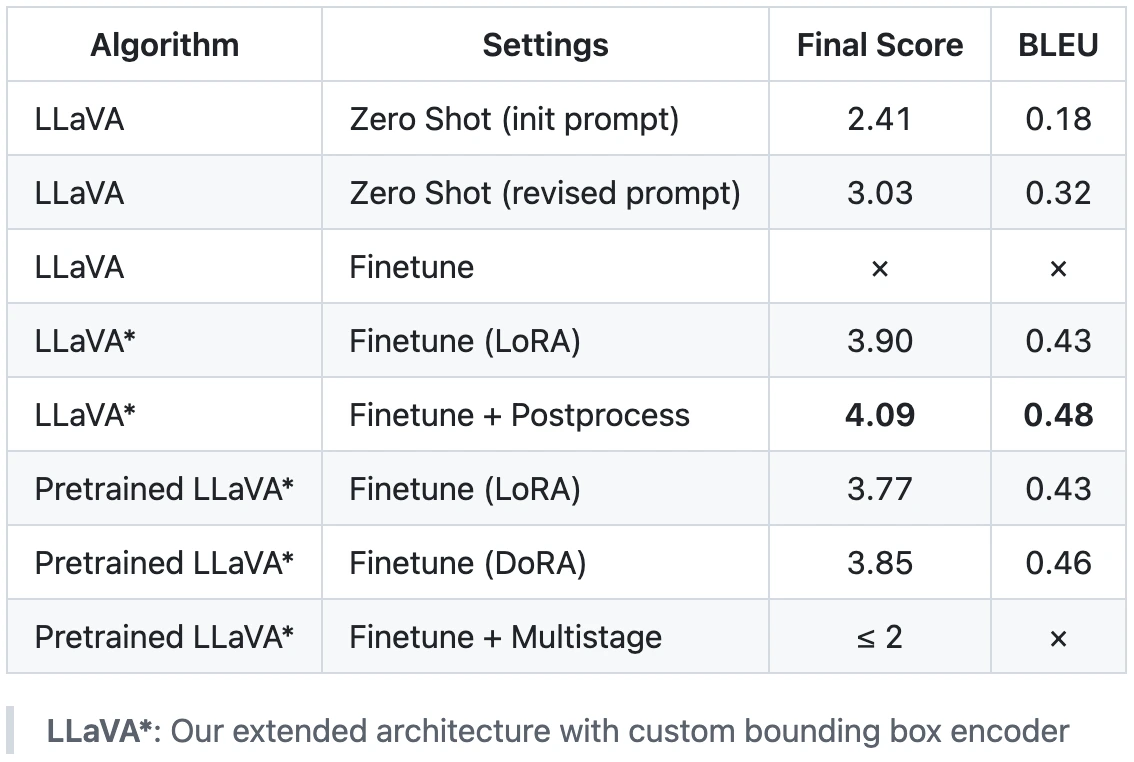
- LoRA fine-tuning with post-processing achieved the best performance (4.09)
- Pre-training both projectors degraded performance due to error propagation from noisy detection labels
- Multi-stage inference (knowledge transfer) did not improve results in our setting
🔧 Methods
- General Perception: Describe all objects affecting the ego vehicle's driving behavior
- Regional Perception: Explain specific objects highlighted in the scene
- Driving Suggestions: Provide actionable driving recommendations based on scene understanding
📸 Figures
📊 Results
🛠 Tech Stack
Other Projects
MOSAIC: Exploiting Compositional Blindness in Multimodal Alignment
A novel multimodal jailbreak framework that targets compositional blindness in Vision-Language Models. MOSAIC rewrites harmful requests into Action–Object–State triplets, renders them as stylized visual proxies, and induces state-transition reasoning to bypass safety guardrails. Published at NTU ML 2025 Fall Mini-Conference (Oral).
PEFT-STVG: Parameter-Efficient Fine-Tuning for Spatio-Temporal Video Grounding
Spatio-Temporal Video Grounding (STVG) localizes objects in video frames that match natural language queries across time. While effective, existing methods require full model fine-tuning, creating significant computational bottlenecks that limit scalability and accessibility.