PEFT-STVG: Parameter-Efficient Fine-Tuning for Spatio-Temporal Video Grounding
Spatio-Temporal Video Grounding (STVG) localizes objects in video frames that match natural language queries across time. While effective, existing methods require full model fine-tuning, creating significant computational bottlenecks that limit scalability and accessibility.
📍 Challenge
🔍 Key Findings
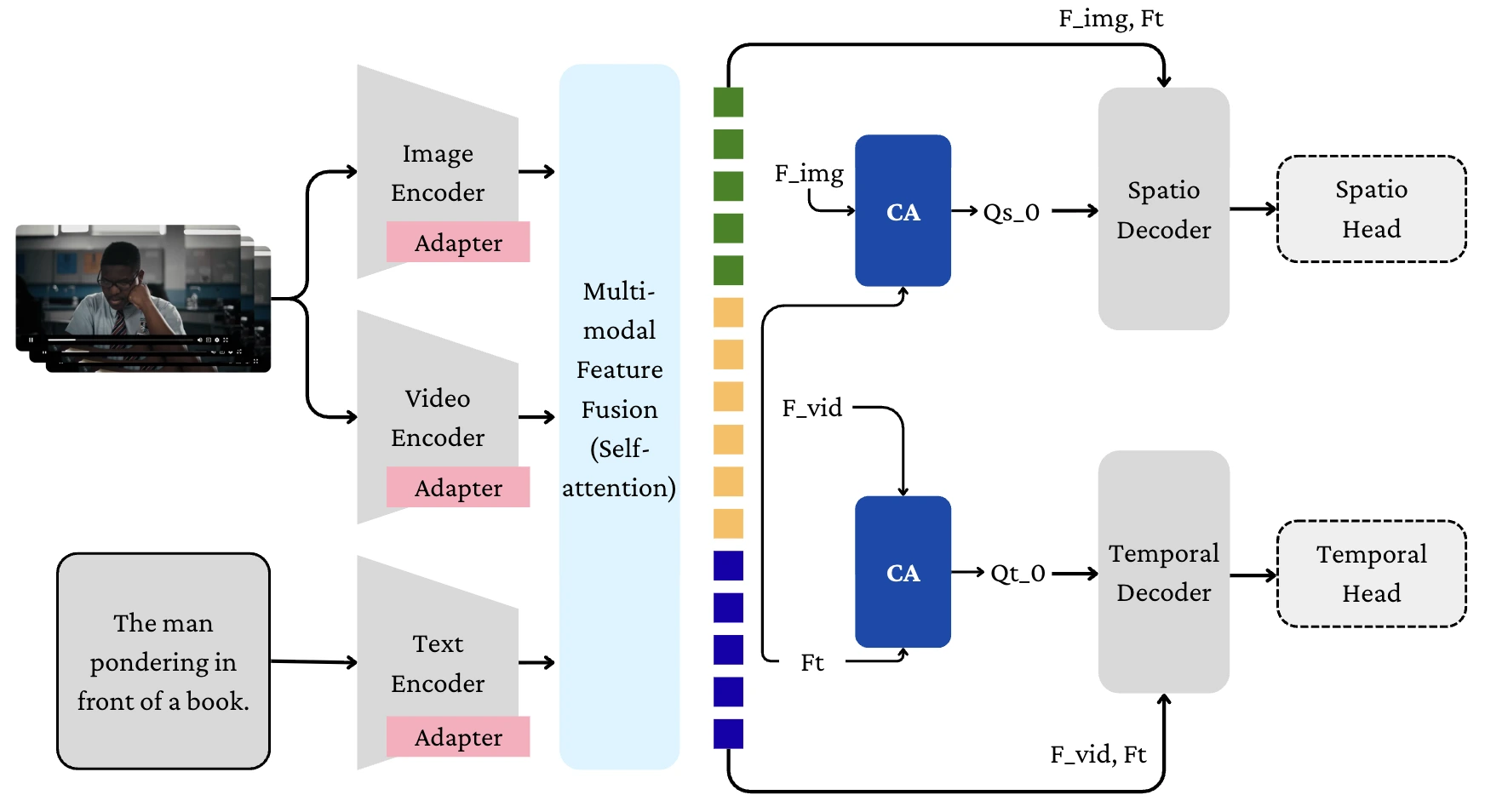
- Early layers align motion cues between modalities
- Later layers align semantic cues for high-level understanding
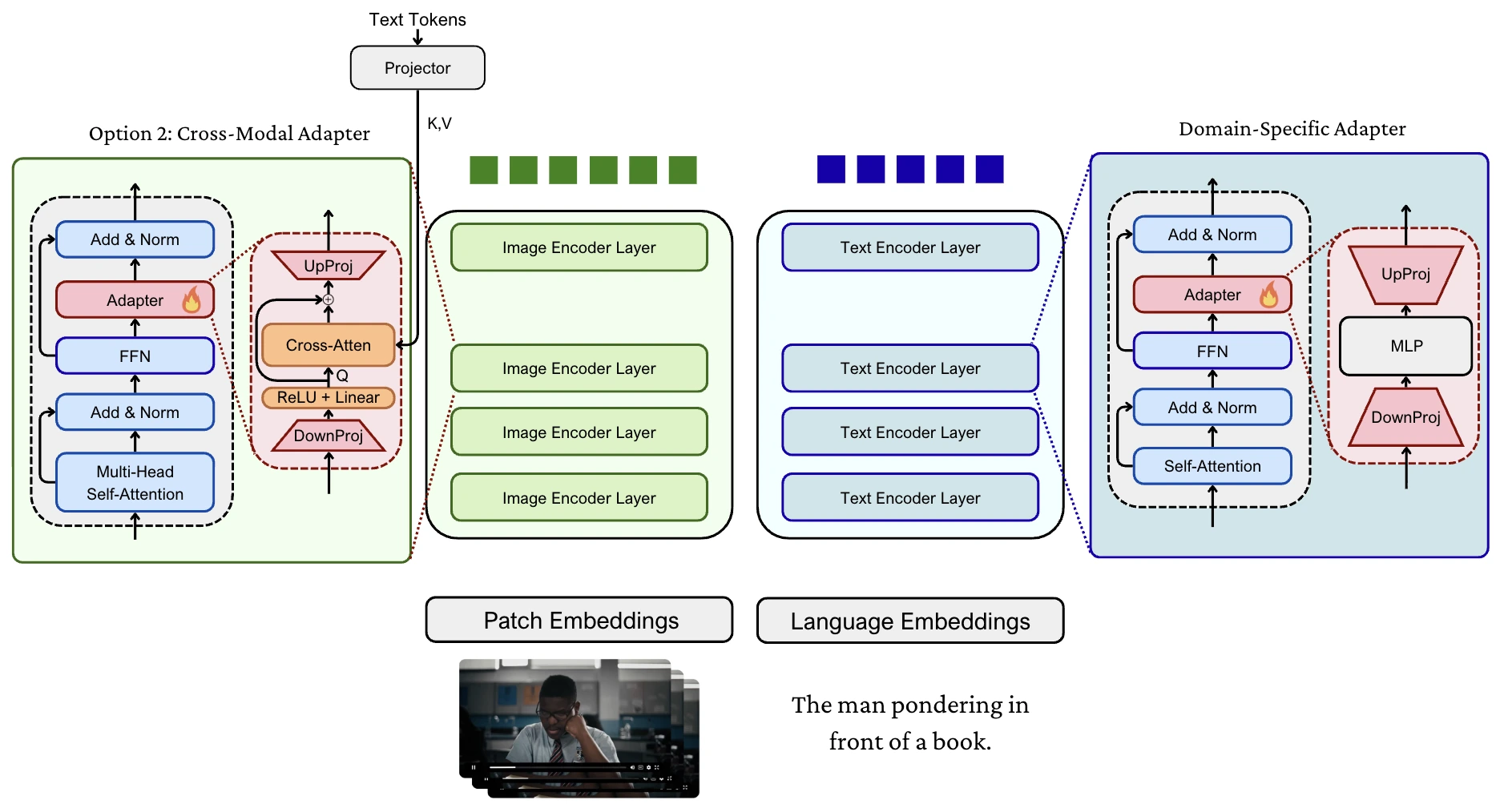
🔧 Methods
📸 Figures
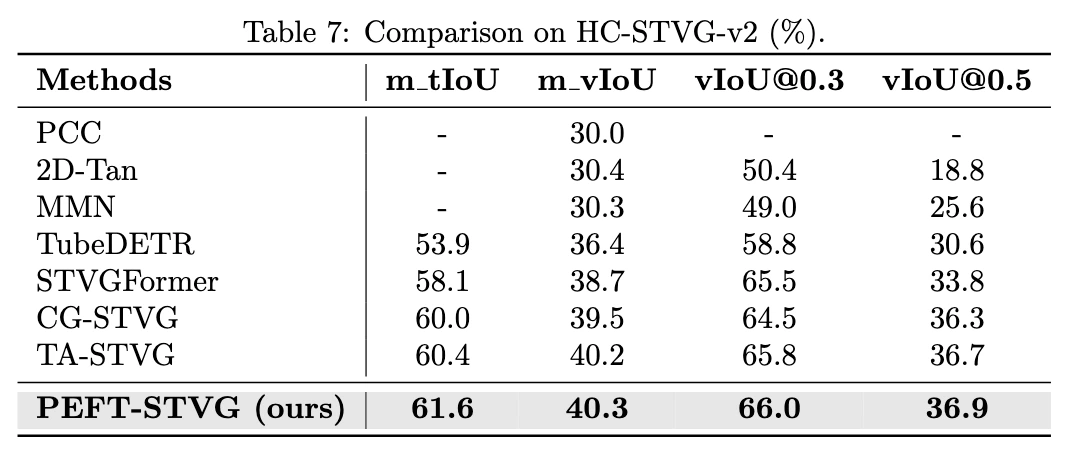
📊 Results
🛠 Tech Stack
Other Projects
MOSAIC: Exploiting Compositional Blindness in Multimodal Alignment
A novel multimodal jailbreak framework that targets compositional blindness in Vision-Language Models. MOSAIC rewrites harmful requests into Action–Object–State triplets, renders them as stylized visual proxies, and induces state-transition reasoning to bypass safety guardrails. Published at NTU ML 2025 Fall Mini-Conference (Oral).
CPF-Net: Continuous Perturbation Fusion Network for Weather-Robust LiDAR Segmentation
A continuous perturbation fusion network for weather-robust LiDAR segmentation, achieving SOTA performance on the SemanticKITTI -> SemanticSTF dataset.